Section 10.2: Hypothesis Tests for a Population Proportion
Objectives
By the end of this lesson, you will be able to...
- explain the logic of hypothesis testing
- test hypotheses about a population proportion
- test hypotheses about a population proportion using the binomial probability distribution
For a quick overview of this section, watch this short video summary:
The Logic of Hypothesis Testing
Once we have our null and alternative hypotheses chosen, and our sample data collected, how do we choose whether or not to reject the null hypothesis? In a nutshell, it's this:
If the observed results are unlikely assuming that the null hypothesis is true, we say the result is statistically significant, and we reject the null hypothesis. In other words, the observed results are so unusual, that our original assumption in the null hypothesis must not have been correct.
There are generally three different methods for testing hypotheses:
- the classical approach
- P-values
- confidence intervals
Because P-values are so much more widely used, we will
be focusing on this method. You will be required to include P-values
for your homework and exams.
We will also frequently look at both P-values and confidence intervals to make sure the two methods align.
P-Values
In general, we define the P-value this way:
The P-value is the probability of observing a sample statistic as extreme or more extreme than the one observed in the sample assuming that the null hypothesis is true.
The Sample Proportion
In Section 8.2, we learned about the distribution of the sample proportion, so let's do a quick review of that now.
In general, if we let x = the number with the specific characteristic, then the sample proportion, ![]() , (read "p-hat") is given by:
, (read "p-hat") is given by:
![]()
Where ![]() is an estimate for the population proportion, p.
is an estimate for the population proportion, p.
We also learned some information about how the sample proportion is distributed:
Sampling Distribution of 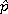
For a random sample of size n such that n≤0.05N (in other words, the sample is less than 5% of the population),
- The shape of the sampling distribution of is approximately normal provided
np(1-p)≥10 - The mean of the sampling distribution of is
 .
. - The standard deviation of the sampling distribution of is

Why are these important? Well, suppose we take a sample of 100 online students, and find that 74 of them are part-time. You might recall that based on data from elgin.edu, 68.5% of ECC students in general are par-time. So is observing 74% of our sample unusual? How do we know - we need the distribution of ![]() !
!
So what we do is create a test statistic based on our sample, and then use a table or technology to find the probability of what we observed. Here are the details.
Testing Claims Regarding the Population Proportion Using P-Values
In this first section, we assume we are testing some claim about the population proportion. As usual, the following two conditions must be true:
- np(1-p)≥10, and
- n≤0.05N
Step 1: State the null and alternative hypotheses.
| Two-Tailed H0: p = p0 H1: p ≠ p0 |
Left-Tailed H0: p = p0 H1: p < p0 |
Right-Tailed H0: p = p0 H1: p > p0 |
Step 2: Decide on a level of significance, α, depending on the seriousness of making a Type I error. ( α will often be given as part of a test or homework question, but this will not be the case in the outside world.)
Step 3: Compute the test statistic,  .
.
Step 4: Determine the P-value.
Step 5: Reject the null hypothesis if the P-value is less than the level of significance, α.
Step 6: State the conclusion.
Calculating P-Values
Right-Tailed Tests

Left-Tailed Tests

Two-Tailed Tests
In a two-tailed test, the P-value = 2P(Z > |zo|).

It may seem odd to multiply the probability by two, since "or more extreme" seems to imply the area in the tail only. The reason why we do multiply by two is that even though the result was on one side, we didn't know before collecting the data, on which side it would be.
The Strength of the Evidence
Since the P-value represents the probability of observing our result or more extreme, the smaller the P-value, the more unusual our observation was. Another way to look at it is this:
The smaller the P-value, the stronger the evidence supporting the alternative hypothesis. We can use the following guideline:
- P-value < 0.01: very strong evidence supporting the alternative hypothesis
- 0.01 ≤ P-value < 0.05: strong evidence supporting the alternative hypothesis
- 0.05 ≤ P-value < 0.1: some evidence supporting the alternative hypothesis
- P-value ≥ 0.1: weak to no evidence supporting the alternative hypothesis
These values are not hard lines, of course, but they can give us a general idea of the strength of the evidence.
But wait! There is an important caveat here, which was mentioned earlier in the section about The Controversy Regarding Hypothesis Testing. The problem is that it's relatively easy to get a small p-value - just get a really large sample size! So the chart above is really with the caveat "assuming equal sample sizes in comparable studies, ..."
This isn't something every statistics text will mention, nor will every instructor mention, but it's important.
Example 1
According to the Elgin Community College website, approximately 56% of ECC students are female. Suppose we wonder if the same proportion is true for math courses. If we collect a sample of 200 ECC students enrolled in math courses and find that 105 of them are female, do we have enough evidence at the 10% level of significance to say that the proportion of math students who are female is different from the general population?
Note: Be sure to check that the conditions for performing the hypothesis test are met.
Before we begin, we need to make sure that our sample is less than 5% of the population, and that np0(1-p0)≥10.
Since there are roughly 16,000 students at ECC (source: www.elgin.edu), our sample of 200 is clearly less than 5% of the population. Also,
np0(1-p0) = 200(0.56)(1-0.56) = 49.28 > 10
Step 1:
H0: p = 0.56
H1: p ≠ 0.56
Step 2: α = 0.1
Step 3:  .
.
Step 4: P-value
= 2•P(Z < -1.00) ≈ 0.3187
(Note that this is a 2-tailed test.)
Step 5: Since P-value > α, we do not reject H0.
Step 6: There is not enough evidence at the 5% level of significance to support the claim that the proportion of students in math courses who are female is different from the general population.
Hypothesis Testing Regarding p Using StatCrunch
With Data
With Summary
* To get the counts, first create a frequency table. If you have a grouping variable, use a contingency table. |
Example 2
Consider the excerpt shown below (also used in Example 1, in Section 9.3) from a poll conducted by Pew Research:
Stem cell, marijuana proposals lead in Mich. poll
A recent poll shows voter support leading opposition for ballot proposals to loosen Michigan's restrictions on embryonic stem cell research and allow medical use of marijuana. The EPIC-MRA poll conducted for The Detroit News and television stations WXYZ, WILX, WOOD and WJRT found 50 percent of likely Michigan voters support the stem cell proposal, 32 percent against and 18 percent undecided. The telephone poll of 602 likely Michigan voters was conducted Sept. 22 through Wednesday. It has a margin of sampling error of plus or minus 4 percentage points. (Source: Associated Press)
Suppose we wonder if the percent of Elgin Community College students who support stem cell research is different from this. If 61 of 100 randomly selected ECC students support stem cell research, is there enough evidence at the 5% level of signficance to support our claim?
Note: Be sure to check that the conditions for performing the hypothesis test are met.
Before we begin, we need to make sure that our sample is less than 5% of the population, and that np0(1-p0)≥10.
Since there are roughly 16,000 students at ECC (source: www.elgin.edu), our sample of 100 is clearly less than 5% of the population. Also,
np0(1-p0) = 100(0.50)(1-0.50) = 25 > 10
Step 1:
H0: p = 0.5
H1: p ≠ 0.5
Step 2: α = 0.05
Step 3: We'll use StatCrunch.
Step 4: Using StatCrunch:
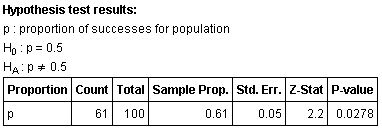
Step 5: Since P-value < α, we reject H0.
Step 6: Based on this sample, there is enough evidence at the 5% level of significance to support the claim that the proportion of ECC students who support stem cell research is different from the Michigan poll.
One question you might have is, "What do we do if the conditions for the hypothesis test about p aren't met?" Great question!
In that case, we can no longer say that sample proportion, ![]() , is approximately normally distributed. What we do instead is return to the binomial distribution, and just consider x, the number of successes. Let's do a quick review of binomial probabilities.
, is approximately normally distributed. What we do instead is return to the binomial distribution, and just consider x, the number of successes. Let's do a quick review of binomial probabilities.
A Binomial Refresher
The Binomial Probability Distribution Function
The probability of obtaining x successes in n independent trials of a binomial experiment, where the probability of success is p, is given by
![]()
Where x = 0, 1, 2, ... , n
Using Technology to Calculate Binomial Probabilities
Here's a quick overview of the formulas for finding binomial probabilities in StatCrunch.
Click on Stat > Calculators > Binomial Enter n, p, the appropriate equality/inequality, and x. The figure below shows P(X≥3) if n=4 and p=0.25.
|

Hypothesis Testing Using the Binomial Distribution
Example 3
Traditionally, about 70% of students in a particular Statistics course at ECC are successful. If only 15 students in a class of 28 randomly selected students are successful, is there enough evidence at the 5% level of significance to say that students of that particular instructor are successful at a rate less than 70%?
If we consider the proportion of students who were successful, we can see that np(1-p) = 28(0.7)(1-0.7) = 5.88, which is less than 10. Therefore, the distribution of ![]() will not be normally distributed.
will not be normally distributed.
Step 1:
H0: p = 0.7
H1: p < 0.7
Step 2: α = 0.05
Step 3: We'll use StatCrunch.
Step 4: If we let X = the number of students who were successful, X follows the binomial distribution. For this example, n=28 and p=0.70, and we want P(X≤15). Using StatCrunch:

Step 5: Since P-value < α (though it's very close), we reject H0.
Step 6: Based on this sample, there is enough evidence at the 5% level of significance to support the claim that the proportion of students who are successful in this professor's classes are less than 70%. (Keep in mind that this assumes the students were randomly assigned to that class, which is never the case in reality!)
 This work is licensed under a Creative
Commons License.
This work is licensed under a Creative
Commons License.