Section 1.5: The Design of Experiments
Objectives
By the end of this lesson, you will be able to...
- describe the characteristics of a designed experiment
- explain the steps in designing an experiment
- explain the types of experimental design
- design your own experiment
For a quick overview of this section, watch this short video summary:
Designed Experiments
Before we can talk about what to design an experiment, we first need to know what an experiment is in a statistics context.
A designed experiment is a controlled study in which one or more treatments are applied to experimental units (subjects). The experimenter then observes the effect of varying these treatments on a response variable.
You can see already that we've got quite a few terms. You may want to get the definition sheet that we started back in Section 1.1.
experimental unit - person or object upon which the treatment is applied
treatment - condition applied to the experimental unit
response variable - the variable of interest
factors - variables which affect the response variable
To help clarify all this terminology, let's consider a simple example:
Example 1
Consider the study we looked at in Example 3 in Section 1.2. It was from the New England Journal of Medicine and concerned the low-carb Atkins diet.
If you'd like more detail, there's a copy of the full article through the New England Journal of Medicine. Focus on the "Methods" section for details on the experimental design and sampling procedure.
Once you've reread the articles, try to determine the experimental units, response variable, treatment, and factors from the study. When you're ready, click on the links in the table below to reveal the answer.
| experimental units |
The experimental
units are the people participating in the diets. |
| response variable |
The response
variable is the amount of weight loss and the level of cholesterol. |
| treatment | The treatments
are the various diets. |
| factors | There
are lots of possible factors - genetics, amount of exercise, sleep
habits, and of course - diet! |
Many designed experiments are double-blind. This means that neither the subjects nor the experimenters know who is receiving which treatment. Typically, subjects are assigned to two groups, with one receiving the treatment (like a new medical drug), while the other receives a placebo. This can be key to avoid researcher bias. Suppose, for example, that the previous study was done by the Atkins Institute and researchers new who was on which diet. Don't you think they'd be tempted to try to influence the results somehow?
In some cases, though, a single-blind experiment is preferable. One good example of this might be a study involving a heart medication. In this case, the doctors involved should be aware of who is taking the drug, and who is taking the placebo.
The Steps in Designing an Experiment
Step 1: Identify the problem or claim to be studied.
The statement of the problem needs to be as specific as possible. In order to be complete, you must identify the response variable and the population to
be studied.
Step 2: Determine the factors affecting the response variable.
This is best done by an expert in the field, but we'll be able to do this
for most examples we'll be looking at.
Step 3: Determine the number of experimental units.
In general, more experimental units is better. Unfortunately, time and money
will always be limiting factors, so we have to decide an appropriate number.
We'll talk more about this later on in the course.
Step 4: Determine the level(s) of each factor.
We split factors up into three categories:
- Control: If possible, we try to fix the level of factors that we're not interested in.
- Manipulate: This is the treatment - we manipulate the levels of the variable that we think will affect the response variable.
- Randomize: Often, there are factors we just can't control. To mitigate their effect on the data, we randomize the groups. By randomly assigning experimental units, these factors should be equally spread among all groups.
Step 5: Conduct the experiment.
Step 6: Test the claim.
We'll focus on this step much later in the course - Chapters 9-12. It uses inferential
statistics, where we look at information from a sample and
try to make a generalization about the population.
OK, now that we have the basic process down, let's look at an example using various designs.
We're going to focus on three particular experimental designs - completely randomized, matched-pairs, and randomized block. I'll illustrate all three in the context of determining whether a practice exam helps improve student learning..
Example 2
Suppose we want to determine the effect of using the practice exams on student exam scores. If we do a survey of students and determine which have used the practice exam and which haven't, we might not really know if the practice exam made a difference. Can you see why?
Essentially, it's because "better" students will typically be more willing to use the practice exam. Since the students self-selected whether or not to use it, we don't know if they did better because of the practice exam, or just because they were better students to begin with.
Let's start our design process.
Step 1: Identify the problem or claim to be studied.
We want to study the effectiveness of course supplements on student
success. For the purpose of this study, we'll specify our population
as all Mth120 student at ECC. In addition, we'll characterize "success" based
on the 1st exam score.
Step 2: Determine the factors affecting the response
variable.
There are plenty of factors here, but let's list a few. Obviously,
the use of course supplements is a factor. We might also include intelligence,
previous knowledge, study habits, sleep, diet, number of hours working,
and of course, the instructor! I'm sure you could come up with several
more.
Step 3: Determine the number of experimental
units.
This will depend on which design we use, so let's hold off on this
step until later.
Step 4: Determine the level(s) of each factor.
I'll take the list of factors we have above, and try to fit them into
one of the groups.
- Control: Looking at the list, the only factor I see that we can control would be the instructor - we'll make sure that all the students involved have the same instructor.
- Manipulate: This is the treatment - supplements used. Let's have three levels - reviewing without the video and using the Video Lecture Series.
- Randomize: This is everything else - intelligence, previous knowledge, study habits, sleep, diet, and number of hours working.
That's the basics. Now on to the experiment itself.
Completely Randomized Design
A completely randomized design is when each experimental unit is assigned to a treatment completely at random. (This is similar to simple random sampling.)
In this design, we would randomly select 60 students and randomly split them into two groups with 30 each. One group does not take the practice exam, while the other does. We have the two groups then take the actual exam and we compare results.
Here's a visual:

Matched-Pairs Design
A matched-pair design is when the experimental units are paired up and each of the pair is assigned to a different treatment.
There are a couple ways to do matched-pairs - we could find people who are very similar somehow, and have one do the practice exam and the other not. Unfortunately, there are so many factors affecting performance on the exam, this pretty impractical.
Another way to do a matched-pair design is to have the same individual before and after the treatment. In this case, we could do just that - give the exam, have students study the practice exam, and then give the exam again. The problem with this design is that we don't know if the improvement (if any) is from the practice exam or just from seeing the material again.
A better plan would be to have all individuals take the exam as a "pre-test", then have 30 students take the practice exam, while the rest do not. Then we have the students all take the exam again, and we compare the "before" and the "after".

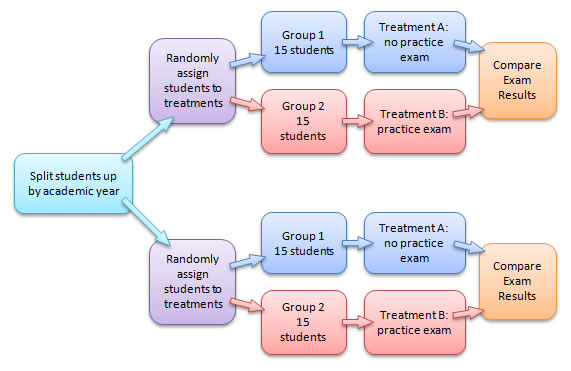
Randomized Block Design
A randomized block design is used when the experimental units are divided into homogeneous groups called blocks. Within each block, the experimental units are randomly assigned treatments. (This is similar to stratified sampling.)
Student maturity is a huge factor in college success. Another idea might be to split our sample by academic year - those in their first year versus those in their second. Essentially, we're stratifying the sample, and then doing a completely randomized design on each of the "strata".
 This work is licensed under a Creative
Commons License.
This work is licensed under a Creative
Commons License.