Section 1.1: Introduction to the Practice of Statistics
Objectives
By the end of this lesson, you will be able to...
- describe what "statistics" means in the context of this course.
- explain the process of statistics
- distinguish between qualitative and quantitative variables
- distinguish between discrete and continuous variables
- determine the level of measurement of a variable
For a quick overview of this section, watch this short video summary:
The first thing we want to look at is exactly what "statistics" is. One reasonable definition might be:
Statistics is the science of collecting, organizing, summarizing, and analyzing information to draw conclusions or answer questions.
So what does that mean? Well, the reason we use data is that often the anecdotal information we have which might appear to be true actually is not.
Case in point: Recently the math department at ECC decided to do some investigation into the success of students in the College Algebra course. Many instructors had poor experiences with students who placed into the course with an ACT score of 23. Those faculty members felt that the cut-off score for placement into College Algebra should be increased to at least 24.
An interesting thing happened when data was collected from a year's worth of students - the students with a 23 on their ACT did just as well as students who placed their via ECC's own placement exam or those who took Intermediate Algebra first. Oops! This was a reminder to even those of us in the math department that there's a reason why the study of statistics was developed - we often have a skewed sense of reality when we only trust our experiences.
At this point, I'd strongly recommend beginning a list of terms with definitions. You might start to get overwhelmed with all the terminology, so a list of terms to refer to would be very helpful.
The Process of Statistics
So what exactly is the study of statistics? Well, it's really a process.
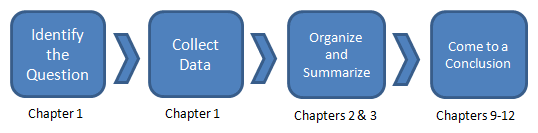 |
|||
| First, we must identify exactly what it is we're hoping to study. We must also determine what our population is. | Next, we select a representative sample using appropriate sampling techniques. | Once we have our data collected, we have to summarize it. We'll do this both numerically and visually with charts. | Finally, we need to analyze it and come to a conclusion. |
The gaps in the middle - Chapters 4-8 - are a mix of sections. Chapter 4 really can stand on its own. It's all about analyzing the relationship between two variables. Chapters 5-8 involve probability and are intended as preparation for the meat of the course in Chapters 9-12.
Identifying the Question
A couple of key comments about identifying the question are needed here. The first thing we really need to consider is what our population is. The population is the group we're studying.
For example, if I'm interested in the studying habits of ECC students, then my population is all ECC students. Since asking every ECC student isn't possible, I would then take a sample, which is a subset of the population. The characteristics of the sample are key. If we select too few or the individuals selected don't represent the population, any conclusions we draw will be meaningless.
A statistic is a numerical summary of a sample. By contrast, a numerical summary of a population is called a parameter.
For example, if we know from ECC data that the average age of all ECC students is 29 (ECC College Facts), that value is a parameter. On the other hand, if we take a sample of 100 students and find that 63% support a new initiative at the college, that is a statistic - since it is only a measure of the sample of 100 students, not the entire student population.
When we simply describe or summarize data, we're using descriptive statistics. When we draw conclusions or extend our results to the population, we're using inferential statistics.
For example, the statistics of 63% from above would be a descriptive statistic, since it is simply a summary of our sample. If we, in turn, make a broad generalization and claim that 63% of all ECC students support the initiative, then that is inferential statistics.
Qualitative or Quantitative
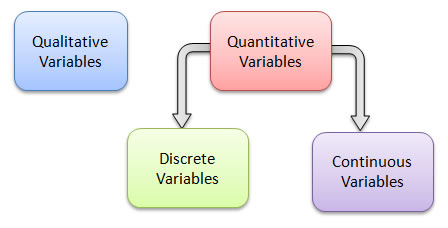
In general, we classify data into two groups: qualitative or quantitative.
Qualitative (or categorical) variables allow for classification of individuals based on some attribute or characteristic.
Quantitative variables provide numerical measures of individuals. Arithmetic operations such as addition and subtraction can be performed on the values of a quantitative variable and will provide meaningful results.
Basically, if a variable describes a quality of an individual - i.e. hair color, political party, etc - then it is qualitative. If a variable is numerical and those numbers have meaning, then it is quantitative. (Not all numbers have meaning numerically - think of an individuals Social Security number.)
Example 1
So, which are they? Here are some examples of data that might be collected. Take a minute and make a note of whether each is qualitative or quantitative. When you're ready, check your answer below.
gender, IQ, ACT score, eye color, area code
Gender - qualitative. No numbers here, so it's an easy choice.
IQ - quantitative. IQs are numbers and can be averaged - with meaning.
ACT score - quantitative. Similar reasoning to IQs.
Eye color - qualitative. Same reasoning as gender.
Area code - qualitative. While they are numbers, you can't have an average area code.
Discrete or Continuous
Quantitative variables can be further split into two groups.
A discrete variable is a quantitative variable that has either a finite number of possible values or a countable number of values. (Countable means that the values result from counting - 0, 1, 2, 3, ...)
A continuous variable is a quantitative variable that has an infinite number of possible values that are not countable.
Most variables are pretty clear, but some can be a bit tricky. An example of a tricky one is time. Say, for example, we're looking at how long we've been waiting for a bus. We count the minutes and seconds, but really those time units are only rounded. There are actually milliseconds, nanoseconds, etc - an infinite number of possibilities in the middle. So actually, any variable that is time is continuous.
Here's a graphical representation of the different ways to classify variables:
Example 2
Time for some examples. Take a minute and make a note of whether each quantitative variable is discrete or continuous. When you're ready, check your answer below.
IQ, ACT score, height, distance commuting, shoe size
IQ - discrete. IQ scores are always integers - 100, 110, 180, etc.
ACT - discrete. Same reasoning as IQ.
Height - continuous. Even though your height might be 5'8", it's really 5.68241231... feet. It's impossible to measure a length exactly!
Distance commuting - continuous. Similar reasoning to height.
Shoe size - discrete. This is a tough one. An argument could be made for either choice, but shoe sizes only come in whole numbers or possibly 1/2 sizes - there is no 8.24 shoe size.
Level of Measurement
Instead of categorizing variables into qualitative or quantitative, we can assign them various "levels" based on their characteristics.
Nominal: A nominal variable is one that simply categorizes or names the variables (i.e. "hair color"). This is the most general level of measurement.
Ordinal: An ordinal variable categorizes, but also has a specific order, like "course grade". This is a little more specific than a nominal variable.
Interval: An interval variable is quantitative (so the values have order as numbers), the differences between values have meaning, but a value of 0 doesn't mean the object has no value. The easiest example is "temperature" - clearly 60°F is more than 30°F, but 0°F doesn't mean it has no temperature and couldn't get colder.
Ratio: The final and most precise level of measurement is ratio. A ratio variable has all the properties of an interval variable, but the ratio of two values has meaning, and a value of zero means the absence of that quantity. A simple example might be "points earned on an exam". A score of 80 is twice the value of a score of 40, and a score of 0 clearly means the student earned no points on the exam. (Note that this is different than a grade of A vs. F, which would just be ordinal.)
Example 3
Time for one last set of examples. Categorize each variable based on its level of measurement as nominal, ordinal, interval, or ratio.
gender, IQ, distance commuting, pain rating 1-10
Gender - nominal. This is just categorizing each individual.
IQ - interval. Larger values do imply a higher IQ, but a 0 IQ doesn't have any meaning - that individual is dead! Also, an individual with an IQ of 120 isn't really "twice as smart" as an individual with an IQ of 60.
Distance commuting - ratio. Unlike IQ, it's possible to have a distance commuting of 0 (working at home!), and a ratio of two distances does have meaning.
Pain rating - ordinal. While it may seem that this is an interval or even a ratio variable, that's not the case. Clearly 7 is more than 5 and 5 is more than 3, but does that difference of 2 mean the same in both cases? What about the difference between a 10 and an 8? Because those differences aren't consisten, this is not an interval variable.
 This work is licensed under a Creative Commons License.
This work is licensed under a Creative Commons License.